17/3/2026
-
6
min
Many industrial companies have a data strategy, yet very few can honestly say their business is better because it. The reason often isn’t technology or talent, but a missing piece in what we call the Triangle of Digitalization — a simple framework that reveals why most data strategies quietly fail.
Many industrial companies have a data strategy, yet very few can honestly say their business is better because it. The reason often isn’t technology or talent, but a missing piece in what we call the Triangle of Digitalization — a simple framework that reveals why most data strategies quietly fail.

Most industrial companies today have a data strategy. They have dashboards, a data lake, AI pilots... Impressive, right? Some even have a Chief Data Officer. They've done their homework. And yet, very few organizations can confidently say: "We are now better because of data."
If this sounds familiar, keep reading.
The issue is rarely a lack of tools or a lack of talent. These guys are usually very clever and have the latest technology. More often than not, the problem is structural — strategic, if you will.
Most failing data strategies are missing one corner of what we call: The Triangle of Digitalization. This framework states that a successful data strategy should start with these simple questions:
Ignore one corner — and the strategy collapses.
Let’s break it down.
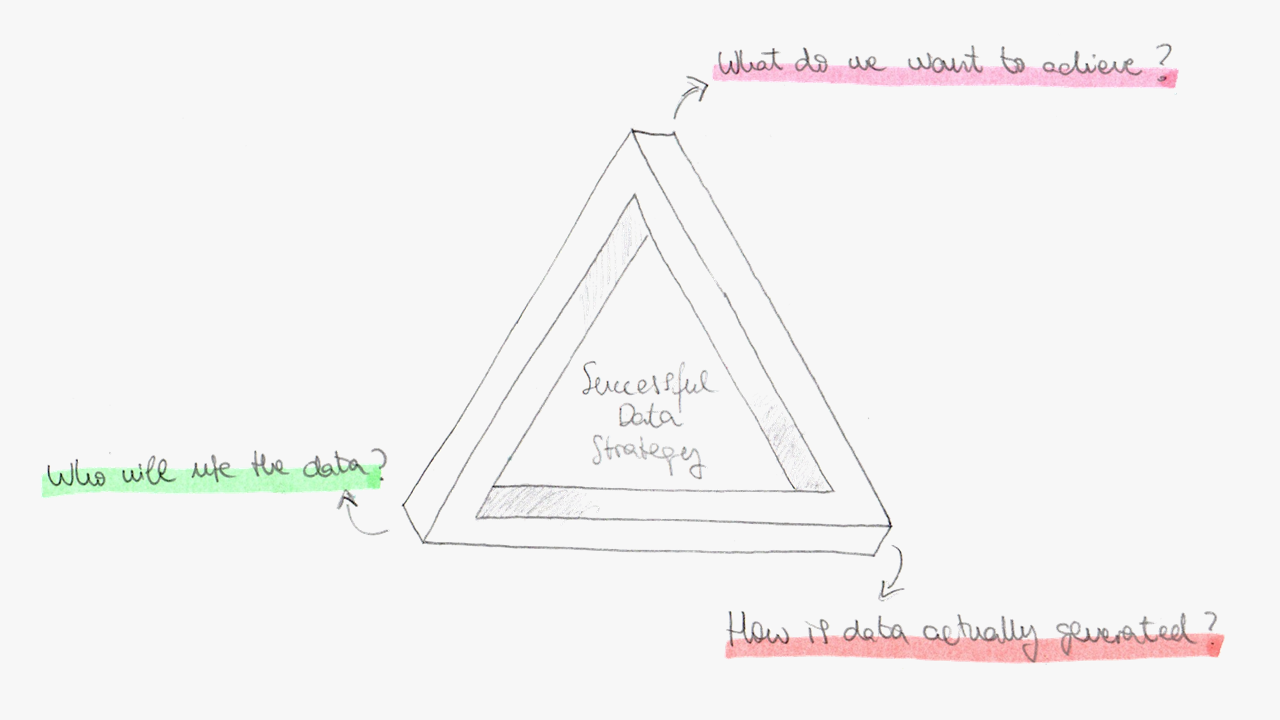
The most common mistake we see? Starting with technology.
"We need AI," "We should centralize everything in the cloud," or "Let’s deploy MQTT." I actually hear this one a lot — the appeal of MQTT in industrial environments deserves its own discussion.
In the end it's understandable because, let's accept it, technology is sexy. We all like a new piece of technology, a new toy to play with. For many managers and engineers, deploying a new tool feels like Christmas Day (or the equivalent in your culture).
But before adopting the next shiny solution, we should ask ourselves: Do we actually need this toy? Is it the right tool for us? Spoiler: many times it isn't.
One of the companies we worked with, invested heavily in getting all their data into a centralized analytics platform. It took a while to read all that data from OPC-UA, Modbus and some funny protocols we hadn't even heard about at that time (seriously).
Two years later, adoption was minimal. The data was there, but no one used it.
Why? Because they didn't begin with the harder questions: What operational decision are we trying to streamline? What KPI? What's our definition of success? Or in plain words:
"What are we trying to improve here?"
For them it rather was "How do we modernize our data infrastructure?" Therefore the result was exactly that: a modern system. A nice shiny new toy that ended up sitting in a corner because no one wanted to play with it.
The second corner is where many strategies break down.
Industrial data is not born in a clean, structured, centralized environment. It's actually really messy. I mean: REALLY messy. We are talking here about heterogeneous machines, some of them decades old, in complex, fragmented networks, sometimes very difficult to reach, using a wide range of protocols, often vendor-specific... This is a huge pain I can't overstate strongly enough.
Yet many data strategies implicitly assume the opposite. They oversimplify the problem.
A typical plan looks like this:
On paper, this seems logical. In practice, this often results in massive ingestion costs, inconsistent data quality, loss of operational context at the edge, and models trained on incomplete data (and you know what they say: garbage in garbage out).
One solutions architect in a large industrial group once told me:
"We thought the hard part was AI."
Their data scientists kept asking for more data — better data.
In industrial environments, messy data doesn’t just create bad dashboards. It creates bad decisions. It amplifies noise.
A resilient data strategy should be built around how data is actually produced. Where is it created? Under what constraints? With what latency requirements? Across which legacy systems? Messy networks? Unreachable data? Reliability? Silos?
Ignoring these constraints does not make them disappear. It simply pushes the complexity downstream, where it becomes more expensive and harder to correct.
Here is the most uncomfortable truth of the day:
"Data strategies fail more often for human reasons than technical ones."
You can have robust pipelines, clean datasets, real-time dashboards, and advanced models. But if people do not trust the output, nothing will change. Or worse, if they just don't want to use the tool because they fear being replaced, or because they just can't be bothered to learn, or just because they are unhappy because they were not involved in the first place.
One machine manufacturer we worked with deployed data collection across all the equipment they produced. The vision was clear. They wanted to analyze operational data to identify performance improvements and remotely diagnose faults. Strategically, it made sense. The business objective was well-defined.
But months after deployment, the data remained largely unused.
In a follow-up discussion, the explanation was simple:
"We don't have the people to analyze it."
The data was there. The platform was there. The organizational capability was not. The third corner failed.
A data strategy only succeeds when the end users are identified and involved in the process from day one. If your organization lacks analytics capabilities, that gap must be addressed explicitly — through hiring, training, or partnerships.
Adoption does not happen by accident. It is designed.
Digital transformation is often framed as a tooling problem. It isn’t. It’s a decision-making problem. So if your strategy isn’t working, ask yourself the three triangle questions.
If one answer is weak, the strategy is weak. Go back and rethink it.
Because ignoring one corner doesn’t just delay ROI — it erodes trust in the entire transformation effort. And rebuilding that trust is far harder than connecting a PLC to the cloud or deploying yet another MQTT broker.
Barbara enables industrial organizations to deploy, orchestrate, and continuously manage distributed applications and AI models directly at the edge — where latency, bandwidth constraints, and data sovereignty cannot be compromised.
Built for complex environments with SCADA systems, PLCs, legacy protocols, and heterogeneous hardware, Barbara helps IT and OT teams move beyond pilots and scale secure edge deployments to thousands of nodes.
If you're working on similar challenges or exploring how edge platforms can support your industrial initiatives, explore more insights on our blog or get in touch with our team to continue the conversation.
Alternatively, you can also start using the platform today.
.jpg)
Most people in industrial automation still believe that hardware is inherently more reliable than software. But many of the assumptions behind that belief were formed decades ago, before connected operations, edge computing, and software-defined industrial systems became a reality. In this article, we challenge five of the most common myths about software in industrial environments.
.jpg)
Industrial digitalization has become unnecessarily complex, with AI-first strategies before they even get started. In this article, we explore a simpler approach: start by connecting one machine, collecting one stream of data, building one dashboard, or automating one workflow. Because starting small is often the smartest way.

Every industrial company today is looking for the same profile: someone who understands machines, networks, data, cloud, and AI. Someone who can connect a PLC, deploy a container, troubleshoot a VPN, and explain why the data pipeline is broken. And... surprise, surprise... they can't find it. In this article we explain why.



