20/5/2026
-
8
min
Industrial digitalization has become unnecessarily complex, with AI-first strategies before they even get started. In this article, we explore a simpler approach: start by connecting one machine, collecting one stream of data, building one dashboard, or automating one workflow. Because starting small is often the smartest way.
Industrial digitalization has become unnecessarily complex, with AI-first strategies before they even get started. In this article, we explore a simpler approach: start by connecting one machine, collecting one stream of data, building one dashboard, or automating one workflow. Because starting small is often the smartest way.

If you work close to the plant floor, you've probably noticed something over the last few years: there’s more and more software inside the plant. More systems connected. More applications processing data. More platforms exchanging information. More dashboards showing real-time operations. And honestly, that’s a good thing.
Or... is it?
Because there are also more acronyms. More platforms. More vendors telling you their solution is THE one. At some point, you’ve probably asked yourself:
“Where do I even start?”
And that’s actually the right question. Because the starting point isn’t a hyperscaler, a 40-page reference architecture, or a master’s degree in data engineering.
The starting point should be the edge.
The place where your machines already are. Where data is born. Where decisions actually matter.
So let’s do exactly that: let’s build a simple edge stack together. Step by step. No vendor pitch. No theory for theory's sake. Just a working architecture you can understand, replicate, and adapt to your plant.
Every data project starts with the same question:
“Where do we put our data?”
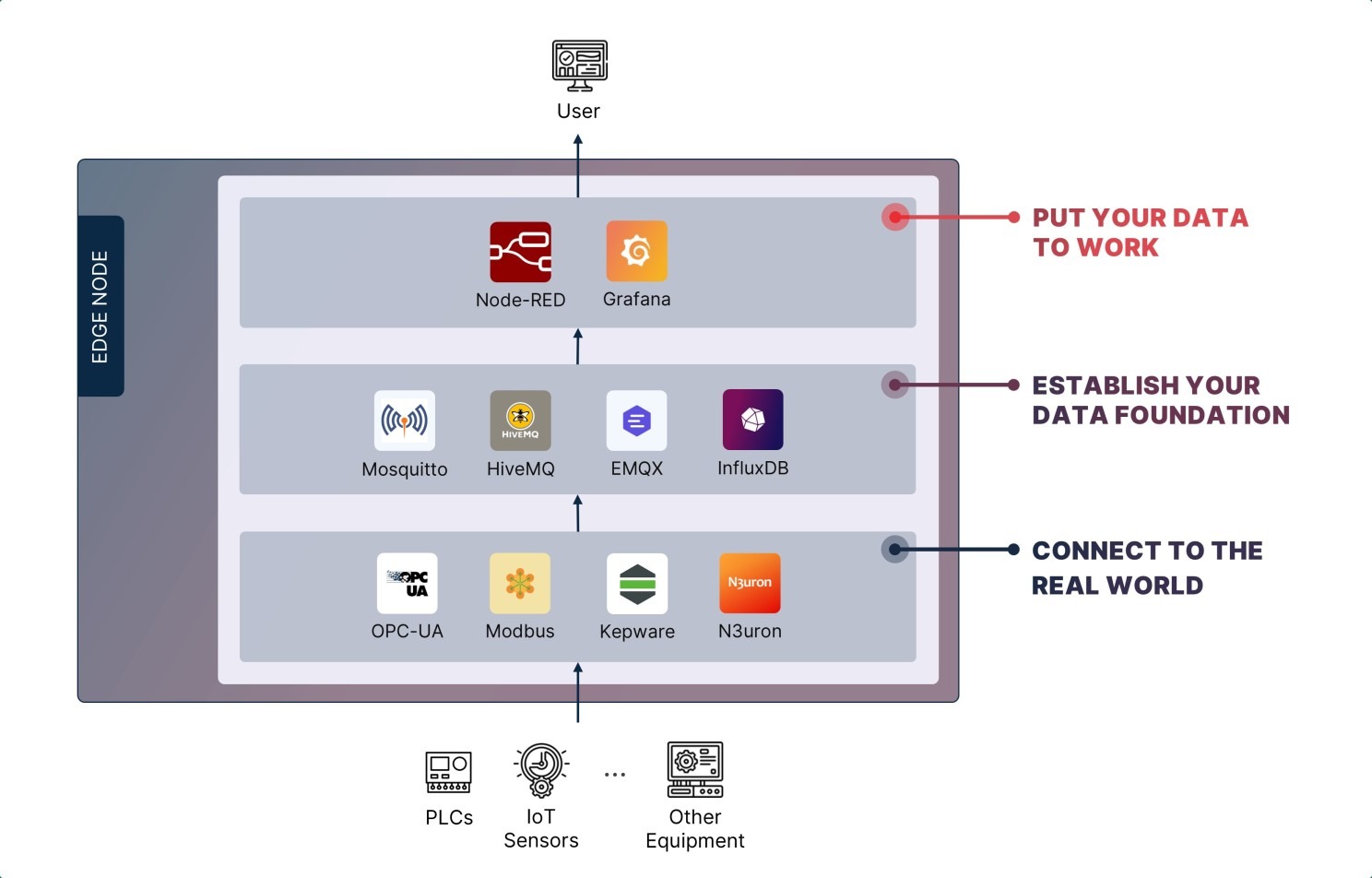
Before dashboards or analytics, we need a local foundation capable of transporting data reliably and storing it efficiently. For a simple but powerful setup, we only need two things: a broker and a database.
Think of MQTT as the postal service for industrial data. Machines, sensors, PLCs, and applications publish data into topics, while other systems subscribe to receive that data. Or, if you prefer, think of it like a public notice board: anyone can post information, and anyone interested can check it out.
Why MQTT? Because it's lightweight, reliable, and built specifically for unreliable networks, which is what you find in industrial environments most often than not. It's also supported almost everywhere.
There are many options available, but some of the most common are Mosquitto, HiveMQ and EMQX.
Industrial systems generate time-based data: Temperature values, vibration measurements, energy consumption... almost everything is referenced to a timestamp. That's not a coincidence; it's the nature of physical processes. And that kind of data needs specialized storage.
That's where time-series databases come in. One of the most popular options at the edge is InfluxDB, optimized for high-frequency telemetry and lightweight enough to run locally. It lets you store millions of datapoints efficiently and query trends without breaking a sweat.
Earlier I said you only needed two things. I lied. Slightly. You actually need a third component: A piece of software that bridges MQTT and the database.
These are typically called ingestors (or ingesters — I never quite knew which was the correct spelling). The job, however, is simple: subscribe to MQTT topics, transform payloads if necessary, and write structured data into the database.
This can be implemented with existing tools like Telegraf, or with a custom lightweight service if you need more control.
And that’s it. A broker, a database, and the thing that connects them. You now have a functional edge data platform running locally.
But this is only the beginning.
Now comes the fun part: We need to collect actual industrial data. That’s what we came here for, right?
And this is where projects become… interesting.
Because industrial environments are messy. Different vendors. Different generations of equipment. Different protocols. Machines older than the engineers operating them. Sometimes older than their bosses. Sometimes older than the bosses' bosses!
The good news is that industrial connectivity has improved enormously in recent years. Today you can deploy field connectors that extract data from almost any equipment by using mostly Modbus or OPC-UA.
However, if you want to move faster and skip a lot of the low-level configuration, industrial middleware platforms like Kepware or N3uron are a more direct approach. They connect to virtually any industrial protocol, normalize the data, and push it directly into MQTT, all from a single interface. For many real-world deployments, this is the more practical path.
Either way, the advice at this stage would be the same: start small. One production line. One substation. A couple of PLCs.
If you've got some weird proprietary protocol that nobody has heard of — leave it for later. It'll still be there when you're ready for it. You need to exercise your edge muscle for a while before fighting the final boss.
Because the goal right now isn't to connect everything. It's to connect something.
Here comes an uncomfortable truth:
"Collecting data is easy. Converting it into value is hard."
But once your edge foundation is running, you suddenly have something incredibly valuable: a local lab fully under your control, ready for experimentation.
To experiment with what? Well, of all the things you could be doing at this stage, let me suggest two simple use cases that are immediately useful.
Sometimes the simplest use case is also the most valuable: visualization. Operators, maintenance teams, and production managers need visibility into operations. Or as the saying goes:
“You can’t operate what you can’t see.”
And for a long time, that visibility either didn't exist or was locked inside expensive SCADA systems that took months to modify.
Grafana changes that. It has become one of the most widely used tools for industrial dashboards because it's easy to deploy, highly flexible, and compatible with InfluxDB out of the box. Within minutes you can build dashboards for virtually any operational metric: energy consumption, cycle times, equipment status... whatever lives in your data. And unlike traditional SCADA projects, these dashboards are fast to build, easy to modify, and accessible from any device.
And all without the need to become a data engineer.
Want to go beyond visualization? Calculate OEE metrics automatically? Trigger alarms? Send notifications when something goes wrong? All without writing a single line of code?
That's where Node-RED comes in. It's a low-code programming environment that lets you build workflows visually. Instead of writing complex logic, you just connect blocks together. Simple in concept, but surprisingly powerful in practice.
Node-RED can pull data from your MQTT broker or InfluxDB, run calculations, apply conditions, and push results back into storage or out to other systems. All through a drag-and-drop interface that runs directly at the edge.
For many industrial use cases, this eliminates the need for heavy software development entirely. And because it runs locally, latency stays low and your operations stay independent from external connectivity.
Industrial digitalization does not begin with AI (I actually didn't mention AI once in this entire article on purpose). It does not begin with massive architectures. And it definitely does not begin with a three-year transformation roadmap.
"Industrial Digitalization begins with one MQTT broker, one database, one connector, one dashboard."
One of the biggest mistakes I see teams make is assuming they need a perfect architecture before they can start.
They don't.
By the way, there's already a name for the stack we just built: the MING stack — MQTT, InfluxDB, Node-RED, and Grafana. So we’re not inventing anything revolutionary here.
And yes, I just wrote (yet) another MING stack article.
Be a dummy. Deploy something simple today. See what breaks, what works, and take it from there.
Start small.
Learn fast.
And build from the edge outward.
Barbara enables industrial organizations to deploy, orchestrate, and continuously manage distributed applications and AI models directly at the edge — where latency, bandwidth constraints, and data sovereignty cannot be compromised.
Built for complex environments with SCADA systems, PLCs, legacy protocols, and heterogeneous hardware, Barbara helps IT and OT teams move beyond pilots and scale secure edge deployments to thousands of nodes.
If you're working on similar challenges or exploring how edge platforms can support your industrial initiatives, explore more insights on our blog or get in touch with our team to continue the conversation.
Alternatively, you can also start using the platform today.
.jpg)
Most people in industrial automation still believe that hardware is inherently more reliable than software. But many of the assumptions behind that belief were formed decades ago, before connected operations, edge computing, and software-defined industrial systems became a reality. In this article, we challenge five of the most common myths about software in industrial environments.
.jpg)
Industrial digitalization has become unnecessarily complex, with AI-first strategies before they even get started. In this article, we explore a simpler approach: start by connecting one machine, collecting one stream of data, building one dashboard, or automating one workflow. Because starting small is often the smartest way.

Every industrial company today is looking for the same profile: someone who understands machines, networks, data, cloud, and AI. Someone who can connect a PLC, deploy a container, troubleshoot a VPN, and explain why the data pipeline is broken. And... surprise, surprise... they can't find it. In this article we explain why.


